Blog





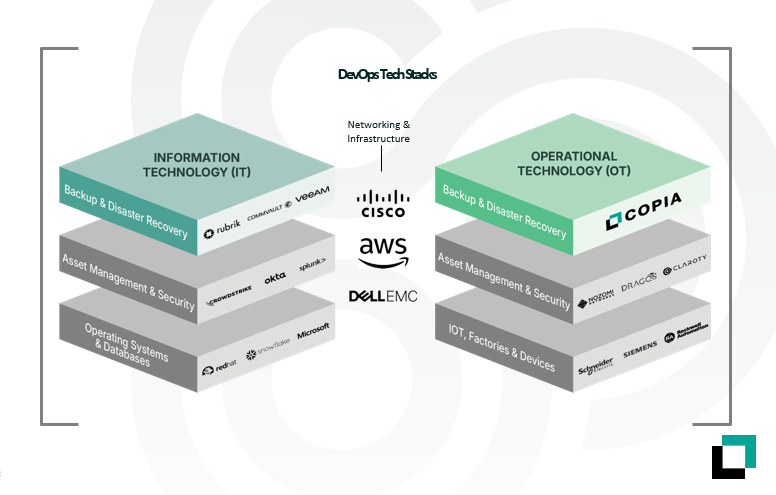





Copia Automation provides unparalleled visibility and control of industrial automation code across multi-vendor devices for continuous quality control, streamlined production, and preemptive crisis management.
Blog

Copia Automation provides unparalleled visibility and control of industrial automation code across multi-vendor devices for continuous quality control, streamlined production, and preemptive crisis management.